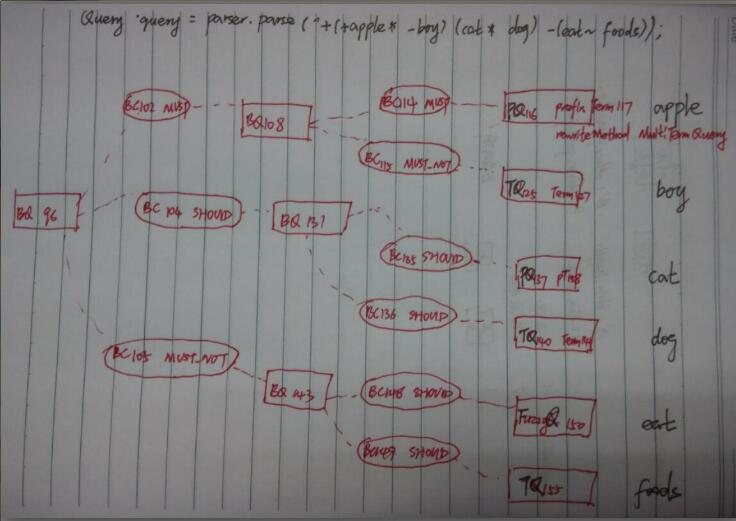
大体流程
IKQueryParser此类是在指定field与query条件下,执行主方法_parse: 1、首先调用IKSegmentation类进行lexeme分词; 2、紧接着调用核心方法accpet将每个lexeme生成对应的tokenbranch(其过程内有一系列关键方法,比如accept方法); 3、生成完整的tokenbranch以后(tokenbranch数据结构有点复杂稍后分析),执行关键方法toQueries将分支数据结构(tokenbranch)转成Query数据结构; 4、执行optimizeQueries方法,优化Query队列结构,减少Query表达式的嵌套,返回相应具体的TermQuery或BooleanQuery。
分析过程
首先理解此类生成的tokenbranch花了很多功夫,以下是一些初始分析过程:
1、初始参数、代码结构解析:

optimizeQueries方法将生成的Query结构优化,防止跟tokenbranch结构一样复杂。

核心方法_parse过程分析:发现生成tokenbranch结构关键方法为accept,accept方法中acceptType表明了正在处理的lexeme与此branch的关系,由于是递归调用理解起来要花一点功夫。

具体accptType值生成方法cheakAccept过程:

2、TokenBranch值的debug过程:


3、TokenBranch值的结构实例:

4、TokenBranch值的结构分析:
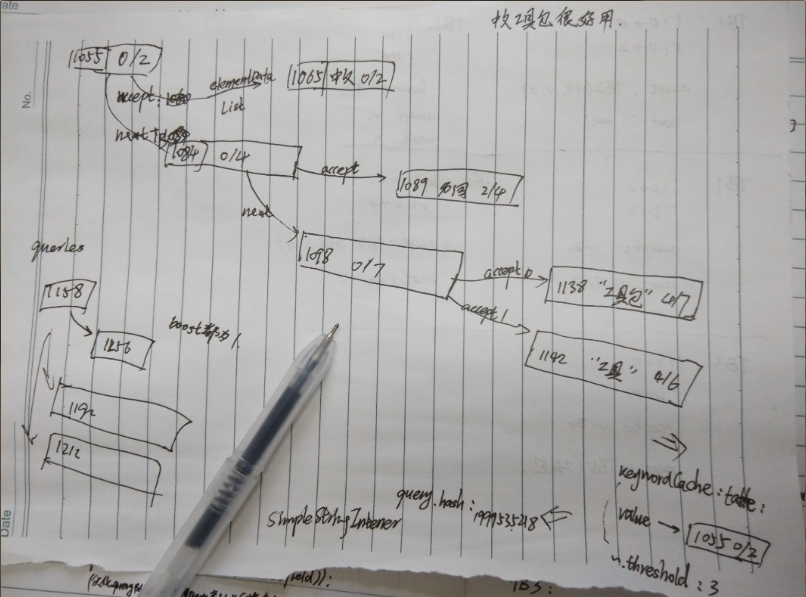
(这是最直观的Tokenbranch结构图,非常有助于理解)
5、最终生成简洁的Query结构数据实例:

参考图:
附:例举Query语法树